
The integration of machine learning (ML) into small-molecule drug discovery has long been heralded as the game-changer that would bring about rapid advancements in the development of new therapeutics. Despite significant investments and the creation of increasingly sophisticated models, the substantial improvements in efficiency and anticipated outcomes have yet to materialise. The reasons for this, as explored in recent research, come down to one key factor: data.
In the emerging era of Biotech 3.0, data is not simply an input but the defining theme of the future of drug discovery. High-quality, large-scale, and reliable data are essential to unleash the full potential of ML in small-molecule research. Even the most advanced algorithms struggle to generate meaningful and accurate predictions without the right data. This article explores why data is the critical enabler of Biotech 3.0 and how automated laboratories are essential for generating the scale and consistency of data required to power the next wave of innovation.
The Role of Data in Machine Learning for Drug Discovery
ML models thrive on data, learning patterns and making predictions based on the datasets they are trained on. However, as outlined in a recent perspective, ‘The future of machine learning for small-molecule drug discovery will be driven by data‘, from Charlotte Deane et al., while fields like computer vision and natural language processing have seen dramatic advances due to the abundance of data, small-molecule drug discovery has been held back by data scarcity and inconsistency.
advanced algorithms and novel architectures have not always yielded substantial improvements in results
The small-molecule field lacks the vast datasets available to other sectors, with much of the data being proprietary or incomplete. As a result, current ML methods often fail to generalise beyond the narrow scope of the data they are trained on, leading to suboptimal outcomes when applied to real-world drug discovery projects. Deane et al. discuss the performance of ML models over time, revealing that there is little or no improvement using CASF-2016 or HIV MoleculeNet and only incremental improvement using USPTO-50k, but no ‘AlphaFold 2 moment’.
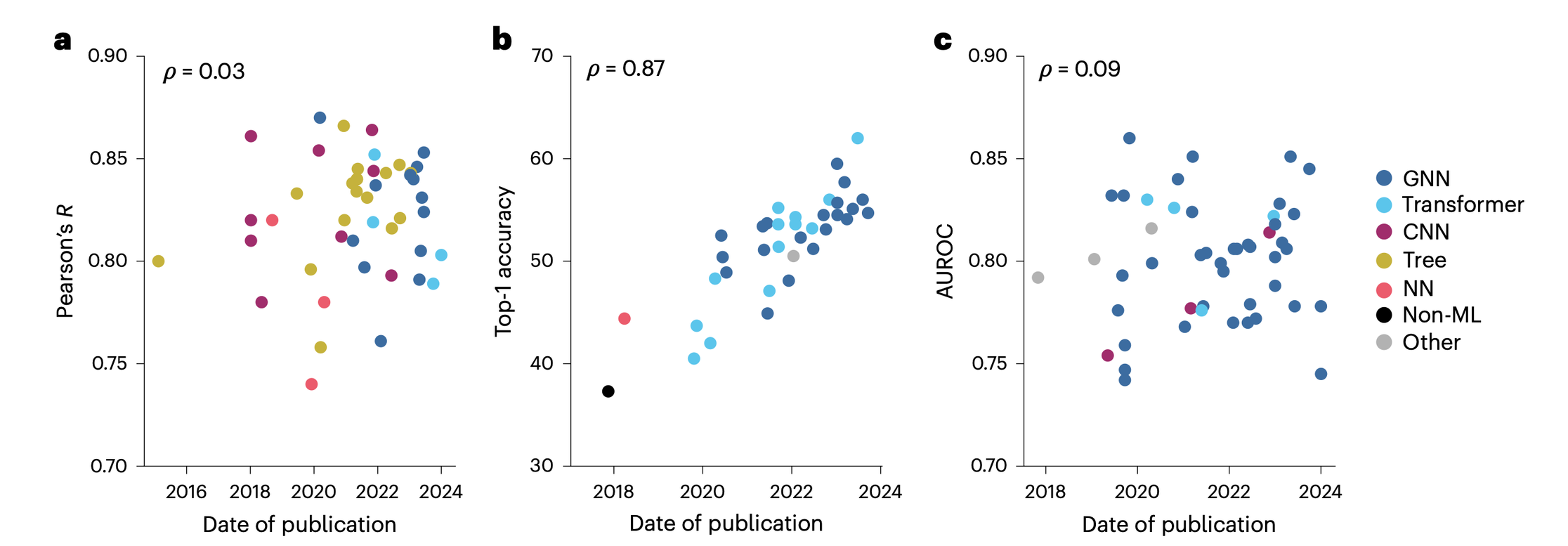
Benchmark performance with respect to publication date
The three benchmarks are CASF-2016, measured by Pearson’s R, the linear correlation between predicting and true binding affinity (a); USPTO-50k, measured by top-1 accuracy, indicating the percentage of times the highest-confidence reaction was correct (b); and HIV MoleculeNet, measured by area under the receiver operating characteristic (AUROC), a performance measurement for classification for binding or not binding at various thresholds (c). Papers are colored by ML architecture employed for the method and the Pearson’s R (ρ) between date of publication and benchmark metric is given in the top-left for each graph. CNN, convolutional neural network; NN, neural network
This discrepancy underscores the importance of focusing not just on algorithms but on the quality and quantity of data available. For ML to reach its full potential in drug discovery, the datasets it relies on must be reliable, expansive, and representative of the complexity of small-molecule interactions. Without this foundation, even the best algorithms cannot deliver the breakthrough improvements the industry seeks.
we propose that a greater focus on the data for training and benchmarking these models is more likely to drive future improvement
Automated Laboratories: Industrial Data Factories
The scarcity of high-quality data is where automation comes into play. Automation provides the precision, scalability, and consistency necessary to generate the vast amounts of reliable data that ML models need to succeed. Traditional laboratory methods, reliant on manual processes, introduce variability and errors that can distort the data used to train ML models. By contrast, automated platforms—such as Arctoris’ Ulysses®—ensure that data is generated consistently and at scale, removing the human element from the equation and dramatically improving the reproducibility of experimental results.
As the recent research explains, ML applications in drug discovery require large datasets, but generating such data manually is expensive, time-consuming, and prone to errors. Automated laboratories are uniquely equipped to overcome these challenges, producing high-throughput, reproducible data far more efficiently than human-driven workflows. This ability to rapidly and accurately generate data is essential for driving the next era of drug discovery, where computational methods play a central role.
Scaling for Success: Addressing Data Quantity and Quality
The limitations of current small-molecule datasets are twofold: they are often too small to train effective ML models, and they frequently suffer from biases, noise, or inconsistencies that can skew the results. For example, as noted in the study, datasets may contain biases introduced by the selection of compounds or experimental conditions, leading to ML models learning spurious correlations rather than meaningful chemical relationships. Additionally, the presence of noisy or incomplete data further undermines the accuracy of these models.
The promise of revolutionizing small-molecule therapeutic development through ML relies not only on the sophistication of algorithms but also on the quality, diversity and quantity of data used for training and validation
Automated laboratories offer a solution to both of these problems. By scaling up data generation and ensuring that the data is consistent and high-quality, automated labs can provide the robust datasets needed to improve model performance. Moreover, automation reduces the potential for human bias or error, ensuring that the data used to train ML models is as reliable and unbiased as possible.
A Data-Centric Future for Drug Discovery
The future of small-molecule drug discovery lies in adopting a data-centric approach.
Automated laboratories like Ulysses® are not just tools—they are essential drivers of innovation, providing the high-quality data that will define the future of drug discovery in the Biotech 3.0 era.
Automated laboratories are critical enablers of this future, providing the infrastructure necessary to produce the high-quality, large-scale data that will power the next generation of ML-driven drug discovery. As Biotech 3.0 unfolds, data will become the cornerstone of innovation, with automated labs at the forefront of this transformation.
In this new era, data is not just an input but the foundation upon which ML models are built. By ensuring that the data used to train these models is reliable, scalable, and diverse, the industry can finally achieve the breakthroughs that have long been anticipated. With automation driving data generation, we are poised to enter a future where drug discovery is faster, more efficient, and more accurate than ever.